WRAM Parallel Access
Introduction
The standard API for data transfers between the host CPU and the DPUs cannot perform transfers in parallel of the DPUs’ execution. At any time, a DPU is either running a program or communicating with the host, but not both in parallel.
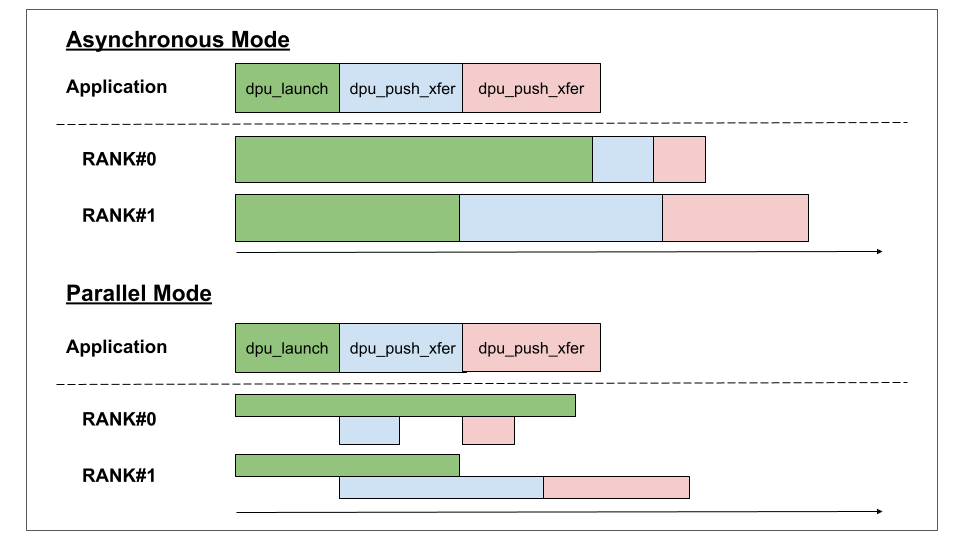
For instance, when executing a dpu_launch followed by a dpu_push_xfer, the data transfer is started once the DPUs have finished their execution. If the asynchronous mode is used, both calls return immediately, but they are still executed sequentially for each rank in the background (see section Asynchronism for more details on the asynchronous mode of execution).
This means that an asynchronous transfer to one rank can happen in parallel of another rank running a program, but there is no overlap of communication and program execution at the DPU level.
Since the SDK release 2024.1, an API is available to perform access to the DPU’s WRAM in parallel of the program execution. This functionality relies on an extension available in the v1B version of UPMEM’s hardware only. It is suitable for small transfer sizes (in the order of few tens of bytes), since the access bandwitdh is limited, but it can be useful for applications where fine-grained communication is needed.
Important notes: this API cannot perform parallel access to the MRAM, only the WRAM can be accessed while the DPUs are running. It is only compatible with v1B hardware, please ensure you have the latest hardware otherwise this feature will not work properly.
The flag DPU_XFER_PARALLEL can be used with function dpu_push_xfer to specify that the transfer should be scheduled in parallel of the DPU program execution.
When executing a dpu_launch with flag DPU_ASYNCHRONOUS followed by a dpu_push_xfer with flag DPU_XFER_PARALLEL, the transfer will be scheduled immediately, without waiting for the DPU execution to finish. Note that if the variable or address targeted does not reference the WRAM, an error DPU_ERR_INVALID_PARALLEL_MEMORY_TRANSFER is triggered.
The picture below shows the difference in execution when using asynchronous and parallel modes.
It is also possible to perform parallel callbacks using the flag DPU_CALLBACK_PARALLEL. Similarly, the callback is then executed in parallel of the DPU program.
Parallel transfers or callbacks respect the FIFO order for execution. They cannot be scheduled before another job that was issued before, whether it is a regular or parallel job.
A parallel job can be both synchronous or asynchronous. If it is synchronous, the call returns when all parallel jobs until the current parallel job are finished. This means, the call will synchronize all scheduled parallel jobs, but not non-parallel jobs.
WRAM FIFOs
A key point when using parallel transfers to the WRAM is the synchronization between the CPU and the DPUs.
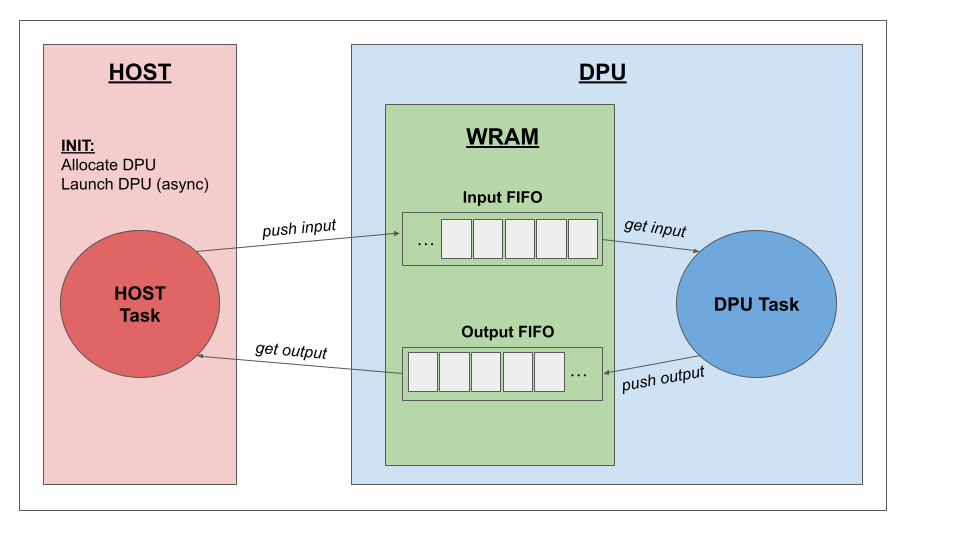
For instance, when the host starts a parallel transfer of data to the DPU WRAM, the DPU must be able to determine when this transfer is done and the data is ready. In order to facilitate the synchronizations, the SDK provides an API for parallel access based on FIFO data structures stored in the DPU’s WRAM. The FIFOs are used to synchronize data exchanges between the host and the DPUs, while ensuring a consistent view of the data at both ends.
After the DPUs have been launched in asynchronous mode, the host program can push data into a DPU’s input FIFO and retrieve data from a DPU’s output FIFO in parallel of the DPU’s execution. The DPU program can get data from an input FIFO, process it, and push a result in an output FIFO. All these operations can be done by the programmer without taking care of the synchronizations which are managed by the API under the hood. The following picture illustrates the flow of execution when the host and the DPUs are synchronized through WRAM FIFOs.
On the DPU side, the following macros are used to declare the FIFOs:
INPUT_FIFO_INIT(fifo_name, fifo_ptr_size, data_size)
OUTPUT_FIFO_INIT(fifo_name, fifo_ptr_size, data_size)
The parameter fifo_name is the variable name, fifo_ptr_size is a strictly positive integer lower or equal to 10, which is equal to the log2 of the FIFO capacity (number of elements it can contain), and data_size (required to be a multiple of 8) is the byte size of one element in the FIFO.
For instance, the call INPUT_FIFO_INIT(q, 5, 8) defines an input FIFO named q with size 2^5 = 32 elements of 8 bytes. The DPU program can perform three main operations on an input FIFO, check its emptiness, access the first element, remove the first element, and it can perform two main operations on an output FIFO, check if the FIFO is full and push data into it.
Note that a WRAM FIFO is either an input FIFO or an output FIFO, but cannot be both at the same time. An input FIFO is filled by the host and emptied by the DPU while an output FIFO is emptied by the host and filled by the DPU.
Two functions are provided to ease the process of repeteadly performing a task on all elements from an input FIFO.
The first function, called process_inputs_all_tasklets, let the next input of the FIFO be handled by all tasklets in parallel. After each tasklet has generated its own result for this unique input, tasklet 0 performs a reduction operation and generates the result in the output FIFO.
The second function, called process_inputs_each_tasklet, let each tasklet take the next input in the FIFO, perform an operation and generate a result in the output FIFO. In this second model, every tasklet work on a different input.
Both functions take as parameter an input and output FIFO, and also function pointers defining the task to be executed.
They also require a pointer to a flag set by the host when it has finished sending inputs. The DPU function keep waiting for new inputs and terminates only when the flag has been set by the host and the input FIFO is empty. The exact prototypes of these functions are found in the Runtime Library documentation here, and the usage of process_inputs_all_tasklets is illustrated in section Code Example.
Host/DPU Communication through FIFOs
The host can push data to an input FIFO and collect data from an output FIFO.
In order to perform operations to a DPU FIFO, it must first create a link to the FIFO using one of the two functions:
dpu_error_t dpu_link_input_fifo(struct dpu_set_t dpu_set, struct dpu_fifo_link_t *link, char *fifo_name)
dpu_error_t dpu_link_output_fifo(struct dpu_set_t dpu_set, struct dpu_fifo_link_t *link, char *fifo_name)
where dpu_set is the set of DPUs for which the FIFO needs to be linked, link is a pointer to a dpu_fifo_link_t structure filled by these function, and fifo_name is the variable name in the DPU program.
Once the link is established, the fifo_link variable can be used to perform transfers with the DPU FIFO.
The host transfers are performed using the functions dpu_fifo_prepare_xfer and dpu_fifo_push_xfer which are comparable to the functions dpu_prepare_xfer and dpu_push_xfer for regular transfers. For pushing data to an input FIFO, the function dpu_fifo_prepare_xfer is used to specify the host buffer containing data to be pushed for each DPU, while for retrieving data from an output FIFO, the same function is used to specify where to store the data collected.
When dpu_fifo_push_xfer is used to push data to an input FIFO, it pushes only one element at a time, and when it is used to collect data from an output FIFO to the host memory, it retrieves all elements from the output FIFO at a time. The prototypes for functions dpu_fifo_prepare_xfer and dpu_fifo_push_xfer are as follows:
dpu_error_t dpu_fifo_prepare_xfer(struct dpu_set_t dpu_set, struct dpu_fifo_link_t *fifo_link, void *buffer)
dpu_error_t dpu_fifo_push_xfer(struct dpu_set_t dpu_set, struct dpu_fifo_link_t *fifo_link, dpu_xfer_flags_t flags)
Where dpu_set is the set of DPUs to target, fifo_link is the link previously obtained with dpu_link_input_fifo or dpu_link_output_fifo, and flags contains the transfer options. As for a regular transfer and for parallel jobs, a call to dpu_fifo_push_xfer can be synchronous or asynchronous. It is triggered in parallel of the DPU execution by default.
When pushing to an input FIFO, it can happen that one of the DPU’s FIFO is full. If this happens, the function retries to push the data after some time, in order to give slack to the DPU for handling elements in its input FIFO. If after a number of retries the FIFO is still full, an error DPU_ERR_WRAM_FIFO_FULL is triggered. The number of retries is 1000 by default and can be modified using function dpu_fifo_set_max_push_retries, and the time between retries is 10 microseconds by default and can be modified using function dpu_fifo_set_time_for_push_retries.
There are different reasons for which the DPU could fail to make progress while its input FIFO is full, but in particular it can happen if the DPU’s output FIFO is also full, preventing it to handle any new element from the input FIFO because it has no space to push a new result. Therefore, it is important to collect elements from the output FIFO at a sufficient pace for the FIFO sizes.
Code Example
This section illustrates the WRAM parallel transfers using FIFOs with a toy example.
The DPU’s MRAM contains an array of key-value pairs as positive integers. The DPU program performs a scan of the array, and sum up the values associated to a given key specified by the host program.
Two FIFOs are defined in the DPU program: an input FIFO containing the keys for which the values’ sum needs to be computed, and an output FIFO containing pairs (key, sum) to be returned to the host.
Each DPU tasklet scans a different part of the array and the partial sums of each tasklet are later accumulated. This is achieved with the function process_inputs_all_tasklets which repeteadly take data from the input FIFO, let every tasklet perform an operation on the data, and let tasklet 0 perform a reduction of the partial results of all tasklets. The DPU code is provided below.
#include <stdint.h>
#include <stdio.h>
#include <mram.h>
#include <defs.h>
#include <barrier.h>
#include <wramfifo.h>
// number of elements to scan
#define NR_ELEMS (4 << 10)
#define NR_ELEM_PER_TASKLET (NR_ELEMS / NR_TASKLETS)
// input and output FIFOs' capacity and data size
#define INPUT_FIFO_PTR_SIZE 5
#define INPUT_FIFO_DATA_SIZE 8
#define OUTPUT_FIFO_PTR_SIZE 6
#define OUTPUT_FIFO_DATA_SIZE 16
// flag set to false by the host when no more keys are sent
__host volatile uint64_t active = 1;
// a barrier used to synchronize tasklets
BARRIER_INIT(barrier, NR_TASKLETS);
// input FIFO of 32 elements of 8 bytes, containing keys sent by the host
INPUT_FIFO_INIT(input_fifo, INPUT_FIFO_PTR_SIZE /*=5*/, INPUT_FIFO_DATA_SIZE /*=8*/);
// output FIFO of 32 elements of 16 bytes, containing pairs (key, sum) returned by the DPU
OUTPUT_FIFO_INIT(output_fifo, OUTPUT_FIFO_PTR_SIZE /*=5*/, OUTPUT_FIFO_DATA_SIZE /*=16*/);
// keys and values stored in MRAM
__mram_noinit uint32_t keys[NR_ELEMS];
__mram_noinit uint32_t values[NR_ELEMS];
// WRAM caches for each tasklet to read keys and values
#define CACHE_SIZE 256
uint32_t cache_keys[NR_TASKLETS][CACHE_SIZE];
uint32_t cache_values[NR_TASKLETS][CACHE_SIZE];
// partial sums computed by each tasklet
uint64_t sum_tasklets[NR_TASKLETS];
/**
* This function handles the sum of values with given key
**/
void values_sum_compute(uint8_t* input, void* ctx) {
uint32_t key = *(uint32_t*)input;
uint64_t *sum_tasklets = (uint64_t*)ctx;
sum_tasklets[me()] = 0;
for(uint32_t i = me() * NR_ELEM_PER_TASKLET; i < (me() + 1) * NR_ELEM_PER_TASKLET; i += CACHE_SIZE) {
mram_read(keys + i, cache_keys[me()], CACHE_SIZE * sizeof(uint32_t));
mram_read(values + i, cache_values[me()], CACHE_SIZE * sizeof(uint32_t));
for(int j = 0; j < CACHE_SIZE; ++j) {
if(cache_keys[me()][j] == key)
sum_tasklets[me()] += cache_values[me()][j];
}
}
}
/**
* This function is the reduction executed by tasklet 0 after all tasklets
* have finished handling the input key.
* It produces the final sum which is written in the output fifo.
**/
void values_sum_reduce(uint8_t* input, uint8_t* output, void* ctx) {
uint64_t *sum_tasklets = (uint64_t*)ctx;
uint64_t sum = 0;
for(int i = 0; i < NR_TASKLETS; ++i)
sum += sum_tasklets[i];
uint32_t key = *(uint32_t*)input;
uint64_t *outputVec = (uint64_t*)output;
outputVec[0] = key;
outputVec[1] = sum;
}
int main() {
// Repeatedly takes a key from the input FIFO, process it
// and push the result in the output FIFO.
// Returns when the active flag has been set to false and the input FIFO is empty
process_inputs_all_tasklets(&input_fifo, &output_fifo,
values_sum_compute, values_sum_reduce, sum_tasklets, &barrier, &active);
return 0;
}
The host program allocates and launch a DPU in asynchronous mode and create links to the DPU FIFOs.
Then it enters a loop to push 64 keys (values 0 to 63) to the DPU input FIFO.
It retrieves the results every 32 loop iterations. When retrieving results from the output FIFO, a parallel callback is scheduled to read the key-sum pairs and compare them to the expected result as computed on the host CPU. The host code is provided below.
#include <dpu.h>
#include <stdint.h>
#include <assert.h>
#include <bits/types.h>
#include <stdio.h>
#include <time.h>
// number of elements to scan
#define NR_ELEMS (4 << 10)
// output FIFO's capacity and size
#define OUTPUT_FIFO_PTR_SIZE 6
#define OUTPUT_FIFO_DATA_SIZE 16
#define OUTPUT_FIFO_SIZE ((1 << OUTPUT_FIFO_PTR_SIZE) * OUTPUT_FIFO_DATA_SIZE)
/**
* generate random key-value pairs and send them to the DPU
**/
static void gen_and_send_key_values(struct dpu_set_t dpu_set, uint32_t* keys, uint32_t* values) {
for (int i = 0; i < NR_ELEMS; ++i) {
keys[i] = rand() % 1024;
values[i] = rand() % 1024;
}
DPU_ASSERT(dpu_broadcast_to(dpu_set, "keys", 0, keys, NR_ELEMS * sizeof(uint32_t), DPU_XFER_DEFAULT));
DPU_ASSERT(dpu_broadcast_to(dpu_set, "values", 0, values, NR_ELEMS * sizeof(uint32_t), DPU_XFER_DEFAULT));
}
/**
* Structure to hold data used for the output FIFO flush callback
**/
struct flush_args_t {
uint8_t *output_fifo_data;
struct dpu_fifo_link_t *output_link;
uint64_t* sums;
};
/**
* Read key-sum pairs retrieved from the DPU's output FIFO.
* Check the correctness by comparing with the sum computed on the CPU.
**/
static dpu_error_t flush_output_fifos(struct dpu_set_t rank,
__attribute__((unused)) uint32_t rank_id,
void *args) {
struct dpu_set_t dpu;
struct flush_args_t *flush_args = args;
uint8_t *output_fifo_data = flush_args->output_fifo_data;
uint64_t* sums = flush_args->sums;
DPU_FOREACH(rank, dpu) {
uint16_t sz = get_fifo_size(flush_args->output_link, dpu);
for (int fifo_index = 0; fifo_index < sz; ++fifo_index) {
uint64_t *recv_data = (uint64_t*)get_fifo_elem(flush_args->output_link, dpu,
output_fifo_data, fifo_index);
uint64_t key = recv_data[0];
uint64_t sum = recv_data[1];
printf("key: %lu received sum=%lu (expected=%lu)\n", key, sum, sums[key]);
assert(sum == sums[key]);
}
}
return DPU_OK;
}
int main() {
// allocate one DPU and load the program
struct dpu_set_t dpu_set, dpu;
DPU_ASSERT(dpu_alloc(1, "", &dpu_set));
DPU_ASSERT(dpu_load(dpu_set, "wram_fifo_example", NULL));
// generate random key and value pairs and send them to the DPU
uint32_t *keys = malloc(NR_ELEMS * sizeof(uint32_t));
uint32_t *values = malloc(NR_ELEMS * sizeof(uint32_t));
gen_and_send_key_values(dpu_set, keys, values);
// compute expected sums for functional correctness verification
uint64_t sums[64] = {0};
for(int i = 0; i < NR_ELEMS; ++i) {
if(keys[i] < 64) {
sums[keys[i]] += values[i];
}
}
// create links to the input and output FIFOs of the DPU
struct dpu_fifo_link_t input_link, output_link;
DPU_ASSERT(dpu_link_input_fifo(dpu_set, &input_link, "input_fifo"));
DPU_ASSERT(dpu_link_output_fifo(dpu_set, &output_link, "output_fifo"));
// allocate an array to store the output fifo data read from the DPU
uint8_t *output_fifo_data = calloc(OUTPUT_FIFO_SIZE, 1);
DPU_FOREACH(dpu_set, dpu) {
DPU_ASSERT(dpu_fifo_prepare_xfer(dpu, &output_link, output_fifo_data));
}
// structure holding data for the callback to read the results from the output FIFO
struct flush_args_t flush_args = {output_fifo_data, &output_link, sums};
// variable holding the key to be sent to the input FIFO
uint32_t key = 0;
DPU_FOREACH(dpu_set, dpu) {
DPU_ASSERT(dpu_fifo_prepare_xfer(dpu, &input_link, (void *)(&key)));
}
// launch the DPU in asynchronous mode
DPU_ASSERT(dpu_launch(dpu_set, DPU_ASYNCHRONOUS));
// send key 0 to 63 to the DPU's input FIFO
for(; key < 64; ++key) {
// push new key into the DPU FIFO
DPU_ASSERT(dpu_fifo_push_xfer(dpu_set, &input_link, DPU_XFER_NO_RESET));
// read output FIFO and callback
// since it is emptied at each read, do it after sending 32 inputs
if (((key + 1) % 32) == 0) {
DPU_ASSERT(dpu_fifo_push_xfer(dpu_set, &output_link, DPU_XFER_NO_RESET));
DPU_ASSERT(dpu_callback(dpu_set, flush_output_fifos, &flush_args, DPU_CALLBACK_PARALLEL));
}
}
// Notify the DPU that no more keys will be sent
// The DPU will handle the remaining keys in the input FIFO and terminate
uint64_t active = 0;
DPU_ASSERT(dpu_prepare_xfer(dpu_set, &active));
DPU_ASSERT(dpu_push_xfer(dpu_set, DPU_XFER_TO_DPU, "active", 0,
sizeof(uint64_t), DPU_XFER_PARALLEL));
// wait for the DPU to finish
dpu_sync(dpu_set);
// retrieve last results from the output FIFO
DPU_ASSERT(dpu_fifo_push_xfer(dpu_set, &output_link, DPU_XFER_DEFAULT));
DPU_ASSERT(dpu_callback(dpu_set, flush_output_fifos, &flush_args, DPU_CALLBACK_DEFAULT));
free(output_fifo_data);
dpu_fifo_link_free(&input_link);
dpu_fifo_link_free(&output_link);
dpu_free(dpu_set);
free(keys);
free(values);
return 0;
}